
Khi nhắc đến Googlebot hay Google Spider chúng ta thường được nghe đến thuật ngữ crawl dữ liệu cùng công việc thu thập dữ liệu của nó. Vậy crawl data from website là gì và Googlebot crawl dữ liệu như thế nào? Hãy cùng tìm hiểu điều này qua bài viết dưới đây.
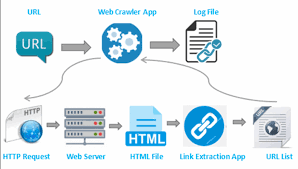
Tổng quan về crawl data from website
1. Crawl data from website là gì?
Crawl dữ liệu hay còn gọi là cào dữ liệu là một thuật ngữ không có gì là xa lạ trong ngành marketing, Dịch Vụ Seo. Vì crawl là kỹ thuật mà các robots của các công cụ tìm kiếm phổ biến hiện nay sử dụng như Google, Yahoo, Bing, Yandex, Baidu… Crawler có công việc chính là thu thập dữ liệu từ một trang web bất kì, hoặc chỉ định trước rồi phân tích cú pháp mã nguồn HTML để đọc dữ liệu và bóc tách thông tin dữ liệu theo yêu cầu mà người dùng đặt ra hoặc các dữ liệu mà Search Engine yêu cầu.
Vậy việc bạn cần crawl data from website của 1 hoặc nhiều wbesite khác cũng tương tự như cách mà Google hay làm. Crawl và sau đó Indexing dữ liệu cào được vào dữ liệu của Google sau cùng là phục vụ cho việc tìm kiếm của chúng ta.
2. Crawler phù hợp với những doanh nghiệp nào?
- Sàn TMĐT, Website rao vặt.
- Tin tức hằng ngày.
- Pháp luật đời sống.
- Website vệ tinh – PBN.
- Website bán hàng Online, Nhập hàng nước ngoài.
Ngoài ra việc phát triển 1 công cụ crawl data from website cũng tốn một ích chi phí, cho nên việc này cũng cần công ty của bạn có năng lực tài chính ổn, xem thêm ở phần chi phí.
3. Công nghệ sử dụng là gì?
SEMTEK Co,. LTD sử dụng các công cụ mới nhất hiện nay để crawl data from website và bóc tách dữ liệu 1 cách chính xác và thông minh. Các ngôn ngữ lập trình crawler tốt nhất hiện tại như:
- Python
- PHP
- Node
- Proxy trong crawl là điều vô cùng quan trọng chống các website Victim chặn việc thu thập của chúng ta, ngoài ra còn có các kỹ thuật khác sử dụng AI để phân tích các website cao cấp và có cấu trúc thay đổi liên tục như Zalo Shop, Tiki, Sendo, Chotot, Muaban …
Lợi ích của việc crawl data from website là gì?
Crawler Data làm giảm tải công việc sáng tạo cho nhân viên Content của bạn, nhân sự là bài toán vô cùng quan trọng của 1 doanh nghiệp đang khởi nghiệp Online. Bạn nghỉ sao khi vào 1 website mà website chỉ có vài sản phẩm, hoặc 1 web đọc tin tức mà chỉ có vài tin ít ỏi ?
Bạn sẽ thoát và tìm 1 trang web giàu nội dung hơn đúng không? chắc chắn rồi vì ta chẳn có gì để xem ở 1 website rổng cả. Bạn không đủ tài chính để thuê 1 đội nhập liệu vài trăm nhân sự? Quá cồng kềnh và tốn nhiều chi phí và thủ tục pháp lý đi kèm cho nhân sự không hề đơn giản.
Nhưng ngược lại nếu bạn đầu tư 1 phần mềm crawl data from website tự động thì bạn có thể giảm tải gần như 90% nhân sự content hiện tại, chỉ giữ 10% nhân sự để chỉnh sửa, viết lách các nội dung quan trọng cho công ty và quản trị công cụ crawler data mà thôi.
Crawler data sẽ giúp website của bạn có nhiều nội dung hơn, nhiều tin tức hơn .., và sẽ có nhiều Users (Khách hàng) hơn.
1. Bật mí bí mật:
Các công ty chuyên bán hàng Bằng Affiliate (Tiếp thị liên kết) thì việc cần 1 công cụ crawl link, crawl data là vô cùng quan trọng, bạn chỉ cần crawler hết data của các sản phẩm ở website khác, sau đó gắn Link ?Ref=Code (Refer) để có thể tăng doanh số của mình 1 cách chóng mặt.
2. Can thiệp vào việc crawl data from website của công cụ tìm kiếm
Mặc dù Google không chấp nhận việc can thiệp thêm của người dùng vào quá trình crawl dữ liệu, và việc crawl website của Google Spider đều tự động và không chịu sự tác động của các nhà quản trị website. Tuy nhiên, vẫn có những phương pháp giúp website được Google crawl dữ liệu thường xuyên hơn.

3. Tạo nội dung mới trên site một cách thường xuyên hơn
Tạo nội dung mới trên website một cách thường xuyên và đều đặn sẽ giúp cho website được công cụ tìm kiếm thu thập dữ liệu một cách thường xuyên hơn. Nhà đầu tư cần đăng các bài viết mới đều đặn mỗi ngày và vào một khung giờ nhất định (chính xác càng tốt) để ngầm tạo một lịch đăng bài với công cụ tìm kiếm, để từ đó được crawl và index thông tin một cách nhanh hơn.
Ngoài ra, những webiste có lượng người truy cập lớn cùng với một lượng dữ liệu lớn trên site hay các trang hoạt động lâu năm và uy tín sẽ có một tần suất crawl data from website dày đặc hơn.
4. Sử dụng các công cụ hỗ trợ index và crawl data from website
Các công cụ như Google Submit Url và Google Fetch của Search Console có thể giúp kéo spider về đến website của nhà đầu tư trong một khoảng thời gian ngắn. Không chỉ giúp crawl dữ liệu, 2 công cụ này còn có thể giúp website có thể submit một liên kết mới tạo trên trang lên bảng kết quả tìm kiếm của Google một cách nhanh nhất có thể. Tuy nhiên, công cụ này chỉ có thể kéo con bot về trong một thời gian ngắn, và nếu website không có một độ uy tín nhất định (Domain authority) thì sẽ cần lặp lại công việc này nhiều lần để gia tăng tốc độ crawl và index.
Ngoài ra, còn một số công cụ hỗ trợ index và crawl ngoài như Google Ping cũng có thể hỗ trợ cho website gia tăng tốc độ crawl dữ liệu và index trang.
Sử dụng crawl data from website bị Google phạt không?
Về việc crawl data có bị phạt không thì cũng là 1 vấn đề gặp phải của các công ty phần mềm cung cấp dịch vụ này. Theo nguyên tắc thì việc crawl dữ liệu SEMTEK Co,. LTD sẽ chia làm 2 khía cạnh như sau:
1. Đối với Google
Việc copy hay crawl là sẽ tạo ra 1 bản sao chép website đó về Database của bạn nếu bạn chỉ crawler 100% nội dung thì có thể bạn sẽ vi phạm chính sác nội dung của Google và DMCA sẽ khởi kiện bạn, Tuy nhiêu đây không phải là việc quá khó qiải quyết vì công cụ của SEMTEK Co,. LTD cung cấp đủ thông minh để Xử lý dữ liệu 1 lần trước khi crawl về nhằm tránh trùm lắp nội dung.
Hãy lưu ý việc này nếu bạn đang crawl hay copy bằng tay website, bài viết của 1 ai đó thì hãy dừng lại ngay vì bạn sẽ bị thuật toán của GOOGLE chặn sớm thôi. Hãy sử dụng công cụ đủ thông minh tái biên soạn lại nội dung của bạn như SEMTEK Co,. LTD nhé. AI của SEMTEK Co,. LTD sẽ giúp bạn xử lý việc này 1 cách nhanh gọn và an toàn.
2. Đối với pháp luật VIỆT NAM
Việt nam có luật bản quyền tác giả được công bố tại Nghị định 22/2018/NĐ-CP quy định chi tiết Luật Sở hữu trí tuệ, Luật sửa đổi Luật Sở hữu trí tuệ về quyền tác giả, quyền liên quan.
Quyền này bảo vệ các quyền lợi cá nhân và lợi ích kinh tế của tác giả trong mối liên quan với tác phẩm này. Một phần người ta cũng nói đó là sở hữu trí tuệ (intellectual property) và vì thế là đặt việc bảo vệ sở hữu vật chất và sở hữu trí tuệ song đôi với nhau, thế nhưng khái niệm này đang được tranh cãi gay gắt.
Quyền tác giả không cần phải đăng ký và thuộc về tác giả khi một tác phẩm được ghi giữ lại ít nhất là một lần trên một phương tiện lưu trữ. Quyền tác giả thông thường chỉ được công nhận khi sáng tạo này mới, có một phần công lao của tác giả và có thể chỉ ra được là có tính chất duy nhất.
Do đó việc copy crawl data from website của 1 website, hay 1 báo điện tử là vi phạm pháp luật ở Việt nam nếu không được đơn vị chủ quyền cho phép.
Liên hệ với SEMTEK để tháo nút thắt cho website của bạn bằng giải pháp về Marketing!
SEMTEK Co,.LTD
🏡 Địa chỉ: 2N Cư Xá Phú Lâm D, Phường 10, Quận 6, TP.HCM
📧 Email: info@semtek.com.vn
☎️ Hotline: (+84)098.300.9285
Các tìm kiếm liên quan:
- Tool crawl dữ liệu từ các website
- Crawl data from website Python
- Crawl data from website PHP
- Crawl data from website online
- Crawl data from website C#
- Crawl data from website Java
Nội dung liên quan :
- Hướng dẫn viết thẻ meta description chuẩn SEO
- SEO la gi? Tại sao SEO lại quan trọng với website?
- Những tiêu chí cần phải có trong SEO website là gì?
- Cách sử dụng Google Analytics đơn giản
- Cách tạo sitemap website

